El modelado de datos es un proceso fundamental en el diseño de bases de datos, que consiste en representar de manera visual y estructurada la organización de los datos y las relaciones entre ellos. El modelado de datos avanzado va más allá de la simple creación de tablas y define una representación más compleja y detallada de los datos, permitiendo una mayor precisión en la definición de las relaciones y reglas que rigen la base de datos.
Modelos de Datos Avanzados
En el modelado de datos avanzado, se utilizan modelos más complejos y detallados para representar la estructura de la base de datos. Algunos de los modelos más utilizados son:
Modelo Entidad-Relación Extendido (EER): Este modelo extiende el Modelo Entidad-Relación (ER) tradicional con conceptos como generalización/especialización, atributos heredados, relaciones recursivas y uniones débiles, lo que permite una representación más precisa y completa de las relaciones entre las entidades.
Modelo Relacional Avanzado: El modelo relacional avanzado incluye conceptos como tablas particionadas, clústeres de tablas y vistas indexadas, lo que mejora el rendimiento y la escalabilidad de la base de datos.
Modelo de Objetos-Relacional (O-R): Combina las características de los modelos de objetos y los modelos relacionales, lo que permite representar objetos complejos y sus relaciones en la base de datos.
Modelo Dimensional: Especialmente utilizado en el diseño de bases de datos para análisis y generación de informes, este modelo organiza los datos en dimensiones y hechos, facilitando el análisis multidimensional y las consultas agregadas.
Principales Elementos del Modelado Avanzado
El modelado de datos avanzado incluye varios elementos que permiten una mayor precisión y flexibilidad en la definición de la base de datos:
Herencia y Generalización: Permite representar relaciones de herencia entre entidades, donde una entidad puede heredar atributos y relaciones de otra entidad.
Atributos Heredados: Los atributos heredados se aplican a una entidad derivada a partir de una entidad padre, lo que permite definir atributos que son comunes a todas las entidades en una jerarquía.
Relaciones Recursivas: Representa relaciones donde una entidad puede estar relacionada consigo misma.
Claves Externas Multivaluadas: Permite que una clave externa pueda estar compuesta por múltiples valores.
Tablas Particionadas: Divide una tabla grande en particiones más pequeñas, lo que mejora el rendimiento y la administración de la base de datos.
Clústeres de Tablas: Agrupa tablas relacionadas físicamente en un mismo espacio de almacenamiento para mejorar el rendimiento.
Herramientas de Modelado Avanzado
Existen diversas herramientas de modelado de datos que permiten trabajar con modelos avanzados, algunas de las más populares incluyen:
Oracle SQL Developer Data Modeler: Herramienta especializada para modelado de datos avanzado en bases de datos Oracle.
Microsoft SQL Server Data Tools: Ofrece capacidades avanzadas de modelado para bases de datos SQL Server.
MySQL Workbench: Proporciona funcionalidades de modelado avanzado para bases de datos MySQL.
Erwin Data Modeler: Herramienta de modelado de datos ampliamente utilizada que soporta diversos SGBD y ofrece capacidades avanzadas.
IBM InfoSphere Data Architect: Herramienta de modelado avanzado para diversas bases de datos IBM.
Resumen
El modelado de datos avanzado es una etapa esencial en el diseño de bases de datos, especialmente en sistemas complejos y de gran escala. Al utilizar modelos más detallados y complejos, se puede representar de manera más precisa la estructura y relaciones de los datos, lo que resulta en una base de datos bien organizada y eficiente.
Seleccionar las herramientas de modelado adecuadas y comprender los conceptos y técnicas avanzadas permitirá a los diseñadores y administradores de bases de datos crear sistemas más robustos y escalables, que se ajusten mejor a las necesidades de los usuarios y aplicaciones.
Modelado Dimensional
El modelado dimensional es una técnica utilizada en el diseño de bases de datos para el análisis de datos y la generación de informes. Este enfoque organiza los datos en estructuras específicas que facilitan el análisis multidimensional, permitiendo a los usuarios obtener información valiosa a partir de grandes volúmenes de datos de manera más eficiente.
Conceptos Clave del Modelado Dimensional
El modelado dimensional se basa en algunos conceptos clave:
Hechos: Representan las medidas o métricas cuantitativas que se desean analizar, como ventas, ingresos o cantidad de productos vendidos.
Dimensiones: Son atributos que proporcionan contexto a los hechos. Por ejemplo, una dimensión puede ser el tiempo, el producto o la ubicación.
Esquema Estrella: Es una estructura común utilizada en el modelado dimensional, donde una tabla central de hechos se conecta directamente con tablas de dimensiones a través de claves foráneas.
Esquema Copo de Nieve: Es una variante del esquema estrella donde las tablas de dimensiones se normalizan en varias tablas, reduciendo la redundancia de datos.
Componentes del Modelado Dimensional
En el modelado dimensional, se utilizan varios componentes para crear un diseño eficiente y efectivo:
Tabla de Hechos: Es la tabla central del esquema que almacena las medidas cuantitativas. Cada fila representa una combinación de dimensiones y contiene los valores numéricos de los hechos.
Tablas de Dimensiones: Son tablas que almacenan los atributos de las dimensiones, como nombres de productos, fechas o ubicaciones. Cada fila representa una única entidad o valor único de una dimensión.
Claves Primarias y Foráneas: Las tablas de dimensiones se relacionan con la tabla de hechos a través de claves primarias y foráneas para establecer las relaciones entre los datos.
Jerarquías: Las dimensiones pueden organizarse en jerarquías para permitir un análisis más profundo y detallado. Por ejemplo, la dimensión de tiempo puede tener jerarquías de año, mes y día.
Atributos Calculados: Son medidas derivadas que se calculan a partir de los datos existentes en la tabla de hechos. Por ejemplo, el margen de beneficio puede ser una medida calculada.
Ventajas del Modelado Dimensional
El modelado dimensional ofrece varias ventajas significativas:
Facilita el Análisis: Las estructuras dimensionales permiten un análisis rápido y flexible de los datos desde diferentes perspectivas.
Mejora el Rendimiento: El diseño optimizado de las tablas de hechos y dimensiones mejora el rendimiento de las consultas y reducir el tiempo de respuesta.
Facilita la Generación de Informes: Las estructuras dimensionales facilitan la generación de informes y análisis de tendencias.
Adaptabilidad a los Usuarios: Los usuarios pueden realizar análisis multidimensionales sin requerir un conocimiento profundo de la estructura de la base de datos.
Reducción de Redundancia: El uso de jerarquías y atributos calculados ayuda a reducir la redundancia y el espacio de almacenamiento necesario.
Resumen
El modelado dimensional es una técnica poderosa para el diseño de bases de datos destinadas al análisis y generación de informes. Al organizar los datos en estructuras específicas, se mejora el rendimiento, se facilita el análisis multidimensional y se proporciona a los usuarios una herramienta efectiva para la toma de decisiones informadas.
Este enfoque es especialmente valioso en entornos donde se manejan grandes volúmenes de datos y se requiere un análisis complejo y flexible para obtener información estratégica y táctica de manera eficiente.
Diseño de Bases de Datos Orientadas a Objetos
El diseño de bases de datos orientadas a objetos es una técnica que combina conceptos de la programación orientada a objetos con la gestión de datos en bases de datos. Este enfoque permite representar los datos en forma de objetos con sus atributos y métodos, lo que brinda una mayor flexibilidad y eficiencia en el manejo de la información.
Características de las Bases de Datos Orientadas a Objetos
Algunas de las características clave de las bases de datos orientadas a objetos son:
Abstracción de Datos: Los datos se representan mediante objetos, que encapsulan tanto los atributos como los métodos que pueden manipularlos.
Herencia: Se pueden definir clases y subclases de objetos, lo que permite la herencia de atributos y métodos entre objetos relacionados.
Polimorfismo: Los objetos pueden tener diferentes formas o estructuras, lo que facilita la reutilización de código y la adaptación a diferentes contextos.
Encapsulamiento: Los datos y las operaciones que los manipulan se agrupan en objetos, lo que garantiza la integridad y la seguridad de los datos.
Persistencia: Los objetos y sus datos asociados pueden almacenarse en la base de datos de forma permanente.
Complejidad de Consultas: Las bases de datos orientadas a objetos permiten consultas complejas que involucran múltiples objetos y relaciones entre ellos.
Modelo de Datos en Bases de Datos Orientadas a Objetos
En las bases de datos orientadas a objetos, el modelo de datos se basa en clases, objetos y relaciones. Algunos conceptos importantes incluyen:
Clases: Representan los tipos de objetos y definen sus atributos y métodos.
Objetos: Son instancias de clases que contienen datos y pueden ejecutar métodos.
Atributos: Son características o propiedades de un objeto que almacenan datos.
Métodos: Son funciones o procedimientos que operan sobre los datos de un objeto.
Relaciones: Representan las asociaciones entre objetos, como la composición, agregación o asociación.
Herencia: Permite que una clase herede los atributos y métodos de otra clase, lo que promueve la reutilización de código.
Implementación de Bases de Datos Orientadas a Objetos
Para implementar bases de datos orientadas a objetos, se utilizan Sistemas de Gestión de Bases de Datos Orientados a Objetos (ODBMS por sus siglas en inglés). Algunos ODBMS populares incluyen:
db4o: Es una base de datos orientada a objetos de código abierto para Java y .NET.
ObjectDB: Es un ODBMS para Java que admite JPA (Java Persistence API).
GemStone/S: Es un ODBMS para Smalltalk que proporciona un ambiente de desarrollo y ejecución completo.
Zope Object Database (ZODB): Es una base de datos orientada a objetos para el framework Zope de Python.
Ventajas de las Bases de Datos Orientadas a Objetos
El diseño de bases de datos orientadas a objetos ofrece varias ventajas significativas:
Modelo más Natural: El enfoque orientado a objetos permite un modelo más natural y directo de representar los datos, lo que facilita su comprensión y mantenimiento.
Reutilización de Código: La herencia y el polimorfismo promueven la reutilización de código, lo que resulta en un desarrollo más eficiente y menos propenso a errores.
Mayor Flexibilidad: La abstracción de datos y la encapsulación permiten una mayor flexibilidad en el manejo de los datos y su estructura.
Complejidad de Consultas: Las bases de datos orientadas a objetos pueden manejar consultas complejas de manera más eficiente y efectiva.
Integridad y Seguridad: El encapsulamiento garantiza la integridad y seguridad de los datos al evitar el acceso no autorizado o la manipulación incorrecta.
Resumen
El diseño de bases de datos orientadas a objetos es una opción poderosa y flexible para el manejo de datos en sistemas que requieren una mayor abstracción y reutilización de código. Al utilizar conceptos de la programación orientada a objetos, se obtiene un modelo más natural y fácil de mantener, lo que resulta en un desarrollo más eficiente y un rendimiento mejorado en el manejo de los datos.
El uso de Sistemas de Gestión de Bases de Datos Orientados a Objetos (ODBMS) permite implementar estas bases de datos y aprovechar al máximo las ventajas que ofrecen en términos de flexibilidad, seguridad y rendimiento en el manejo de los datos.
Modelado de Bases de Datos NoSQL
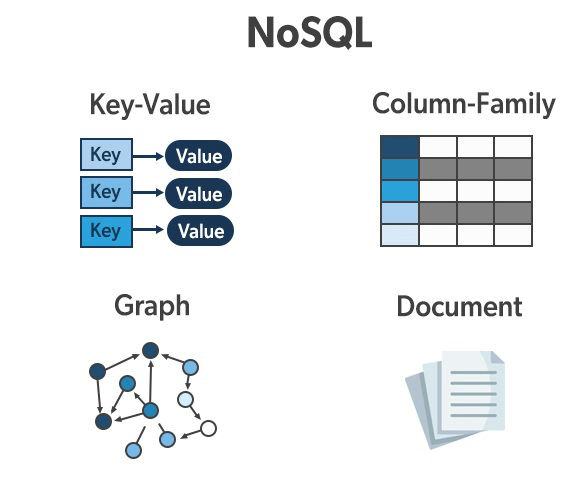
El modelado de bases de datos NoSQL es una técnica utilizada para diseñar y estructurar bases de datos NoSQL, que son sistemas de gestión de bases de datos diseñados para manejar grandes volúmenes de datos no estructurados o semi-estructurados. A diferencia de las bases de datos relacionales, las bases de datos NoSQL no utilizan el modelo de tablas y relaciones, sino que se basan en diferentes modelos de datos para satisfacer necesidades específicas.
Tipos de Bases de Datos NoSQL
Existen varios tipos de bases de datos NoSQL, y cada uno se adapta a diferentes tipos de datos y escenarios de uso:
Bases de Datos Documentales: Almacenan datos en forma de documentos JSON, XML o BSON. Cada documento puede tener estructuras diferentes, lo que permite una mayor flexibilidad en el almacenamiento de datos.
Bases de Datos Clave-Valor: Almacenan datos en pares clave-valor, donde una clave única identifica un valor asociado. Son ideales para almacenar datos simples y de acceso rápido.
Bases de Datos de Grafos: Almacenan datos en forma de nodos y relaciones entre ellos, lo que facilita la representación y el análisis de datos interconectados.
Bases de Datos Columnares: Almacenan datos en columnas en lugar de filas, lo que permite una recuperación eficiente de datos específicos.
Modelado en Bases de Datos Documentales
En las bases de datos documentales, el modelado se basa en la estructura de los documentos almacenados. Algunas características importantes son:
Colecciones: Los documentos se agrupan en colecciones, que son análogas a las tablas en bases de datos relacionales.
Documentos Anidados: Los documentos pueden contener otros documentos como parte de su estructura, lo que permite una mayor complejidad en la organización de los datos.
Índices: Se pueden crear índices en campos específicos para mejorar el rendimiento en consultas.
Esquema Flexible: La estructura de los documentos puede ser flexible y no requiere un esquema fijo, lo que facilita cambios en la estructura de los datos sin afectar a otros documentos.
Modelado en Bases de Datos Clave-Valor
En las bases de datos clave-valor, el modelado es simple ya que los datos se almacenan en pares clave-valor. Algunas consideraciones son:
Claves Únicas: Cada clave debe ser única y se utiliza para acceder rápidamente a los valores asociados.
Datos No Estructurados: Las bases de datos clave-valor son adecuadas para almacenar datos no estructurados o semi-estructurados.
Almacenamiento Eficiente: Debido a su diseño simple, las bases de datos clave-valor ofrecen un almacenamiento eficiente y un acceso rápido a los datos.
Búsqueda por Clave: La recuperación de datos se realiza principalmente a través de la clave, lo que hace que las búsquedas sean rápidas.
Modelado en Bases de Datos de Grafos
En las bases de datos de grafos, el modelado se centra en los nodos y las relaciones entre ellos. Algunas características importantes son:
Nodos: Representan entidades individuales y pueden tener atributos asociados.
Relaciones: Definen conexiones o interacciones entre los nodos.
Propiedades de las Relaciones: Las relaciones pueden tener propiedades que describen la naturaleza de la conexión entre nodos.
Índices: Los índices se utilizan para acelerar la búsqueda de nodos y relaciones.
Consultas Traversales: Las bases de datos de grafos se destacan en consultas que recorren y analizan la estructura de los grafos.
Uso de Bases de Datos NoSQL
Las bases de datos NoSQL se utilizan en una amplia variedad de aplicaciones y escenarios, especialmente cuando se manejan grandes volúmenes de datos y se requiere escalabilidad y rendimiento:
Sitios web y aplicaciones que necesitan manejar una gran cantidad de datos no estructurados o semi-estructurados.
Aplicaciones de redes sociales para gestionar relaciones entre usuarios y publicaciones.
Sistemas de análisis y generación de informes que necesitan un rápido acceso y procesamiento de grandes conjuntos de datos.
Aplicaciones de comercio electrónico que deben manejar grandes volúmenes de productos y transacciones.
Sistemas de recomendación que analizan relaciones complejas entre usuarios y productos.
Resumen
El modelado de bases de datos NoSQL es un enfoque versátil y flexible para el diseño de bases de datos que se adapta a diferentes necesidades y tipos de datos. Al elegir el tipo adecuado de base de datos NoSQL y aplicar un modelado eficiente, se pueden obtener beneficios significativos en términos de rendimiento, escalabilidad y flexibilidad para gestionar grandes volúmenes de datos y satisfacer las necesidades de aplicaciones modernas y de alto rendimiento.