Los modelos de datos son representaciones abstractas y estructuradas de la información que se almacena en una base de datos. Estos modelos definen cómo se organizan, se relacionan y se manipulan los datos en un sistema de gestión de bases de datos (SGBD). Los modelos de datos permiten describir y representar la estructura lógica de una base de datos, así como las operaciones que se pueden realizar sobre ella.
Modelo de Datos Jerárquico
El modelo de datos jerárquico organiza los datos en una estructura en forma de árbol, donde cada registro tiene un único padre y puede tener múltiples hijos. Este modelo se basa en una relación de uno a muchos entre los registros. Es utilizado principalmente en aplicaciones que requieren una estructura de datos rígida y predefinida, como sistemas de archivos y sistemas de gestión de información científica.
Modelo de Datos de Red
El modelo de datos de red es similar al modelo jerárquico, pero permite relaciones de muchos a muchos a través de punteros. Utiliza una estructura en forma de grafo, donde los registros se conectan mediante enlaces. Este modelo ofrece una mayor flexibilidad en la representación de las relaciones entre los datos y es utilizado en aplicaciones como sistemas de gestión de bibliotecas y sistemas de telecomunicaciones.
Modelo de Datos Relacional
El modelo de datos relacional es el modelo más comúnmente utilizado en la actualidad. Organiza los datos en tablas relacionadas, donde cada tabla representa una entidad y las relaciones entre las tablas se establecen mediante claves primarias y claves foráneas. Este modelo ofrece una estructura flexible y permite consultas complejas utilizando el lenguaje SQL. Los sistemas de gestión de bases de datos relacionales (SGBDR), como Oracle, MySQL y PostgreSQL, son ampliamente utilizados en aplicaciones empresariales y comerciales.
Modelo de Datos NoSQL
El modelo de datos NoSQL (Not Only SQL) es una categoría amplia que abarca diferentes enfoques de bases de datos no relacionales. Estas bases de datos están diseñadas para manejar grandes volúmenes de datos no estructurados o semiestructurados, como documentos, datos de redes sociales y datos de sensores. Los modelos NoSQL, como el modelo de documentos, el modelo de clave-valor y el modelo de grafos, ofrecen una mayor flexibilidad y escalabilidad en comparación con los modelos relacionales.
Modelo de Datos Orientado a Objetos
El modelo de datos orientado a objetos combina los conceptos de la programación orientada a objetos con las bases de datos. Permite representar y almacenar objetos complejos con sus atributos y relaciones. Este modelo es utilizado en aplicaciones donde la estructura de los datos se asemeja a objetos del mundo real, como en sistemas de información geográfica y sistemas de diseño asistido por computadora.
Resumen
Los modelos de datos son herramientas fundamentales en la gestión de bases de datos. Cada modelo tiene sus propias características y se adapta a diferentes necesidades y escenarios. El modelo relacional es ampliamente utilizado en aplicaciones empresariales, mientras que los modelos NoSQL son adecuados para el manejo de grandes volúmenes de datos no estructurados. Los modelos de datos jerárquico, de red y orientado a objetos también tienen su lugar en aplicaciones específicas. Comprender los modelos de datos es esencial para diseñar y gestionar eficientemente las bases de datos y aprovechar al máximo la información almacenada en ellas.
Modelo Relacional
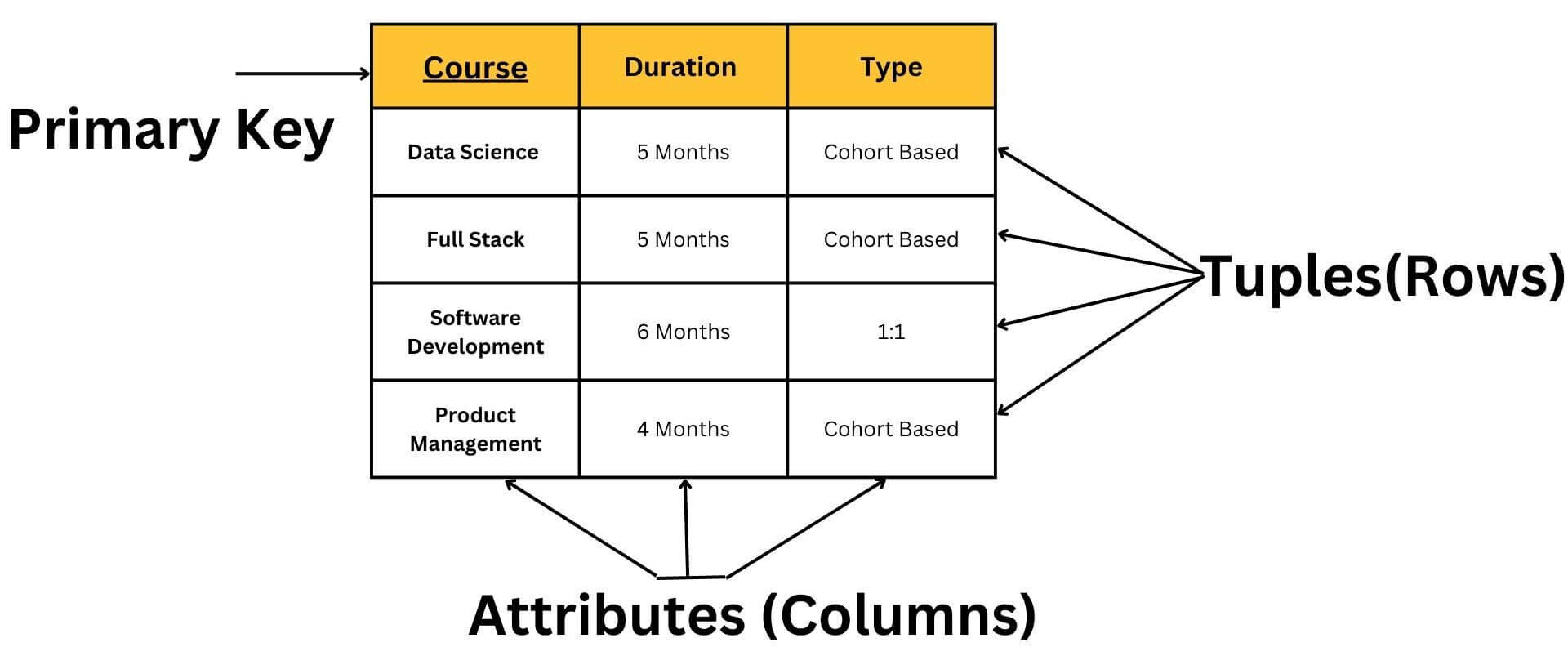
El modelo relacional es un modelo de datos ampliamente utilizado en la gestión de bases de datos. Fue propuesto por Edgar F. Codd en la década de 1970 y se basa en el concepto de tablas relacionadas. En este modelo, los datos se organizan en tablas, y las relaciones entre las tablas se establecen mediante claves primarias y claves foráneas.
Tablas en el Modelo Relacional
En el modelo relacional, una tabla es una estructura que almacena datos relacionados de una entidad específica. Cada tabla se compone de filas y columnas. Las columnas representan los atributos o características de la entidad, y cada fila de la tabla, también conocida como registro, contiene los valores correspondientes a cada atributo para una instancia específica de la entidad.
Registros en el Modelo Relacional
Un registro en el modelo relacional representa una instancia o una ocurrencia específica de una entidad. Cada registro se identifica de manera única dentro de una tabla mediante una clave primaria. Los registros son las unidades individuales de información en una tabla y contienen los valores correspondientes a cada atributo de la entidad.
Atributos en el Modelo Relacional
Los atributos en el modelo relacional son las características o propiedades de una entidad que se almacenan en una tabla. Cada columna de una tabla representa un atributo específico, y los valores en esa columna representan los datos correspondientes a ese atributo para cada registro. Los atributos pueden ser de diferentes tipos, como enteros, cadenas de texto, fechas, booleanos, entre otros.
Relaciones en el Modelo Relacional
Las relaciones en el modelo relacional se establecen mediante claves primarias y claves foráneas. Una clave primaria es un atributo (o una combinación de atributos) que identifica de forma única a cada registro en una tabla. Una clave foránea, por otro lado, es un atributo en una tabla que establece una relación con la clave primaria de otra tabla. Esto permite establecer relaciones uno a uno, uno a muchos o muchos a muchos entre las tablas.
Operaciones en el Modelo Relacional
El modelo relacional permite realizar diversas operaciones para manipular los datos almacenados en las tablas. Algunas de las operaciones más comunes incluyen:
Consulta (SELECT): Permite recuperar datos específicos de una o varias tablas utilizando condiciones y criterios de búsqueda.
Inserción (INSERT): Permite agregar nuevos registros a una tabla.
Actualización (UPDATE): Permite modificar los valores de los atributos de uno o varios registros en una tabla.
Borrado (DELETE): Permite eliminar registros de una tabla.
Resumen
El modelo relacional, basado en tablas, registros y atributos, ha sido una piedra angular en la gestión de bases de datos durante décadas. Proporciona una estructura flexible y eficiente para almacenar y relacionar datos. Las tablas representan entidades, los registros contienen los valores de los atributos y las relaciones se establecen mediante claves primarias y claves foráneas. Comprender y aplicar adecuadamente el modelo relacional es esencial para el diseño, la implementación y el mantenimiento exitoso de bases de datos relacionales.
Claves Primarias y Claves Foráneas
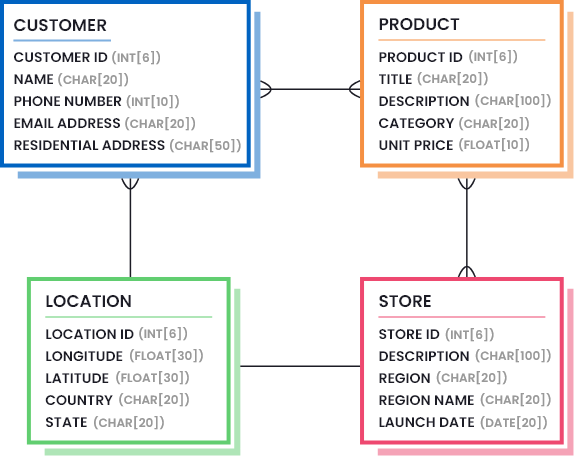
En el modelo relacional de bases de datos, las claves primarias y las claves foráneas son elementos clave para establecer relaciones entre tablas. Estas claves permiten identificar y relacionar los registros de manera única, lo que es fundamental para mantener la integridad y consistencia de los datos.
Claves Primarias
Una clave primaria es un atributo (o una combinación de atributos) que identifica de forma única a cada registro en una tabla. Cada tabla en una base de datos relacional debe tener una clave primaria definida. La clave primaria garantiza que no haya duplicados en la tabla y proporciona un identificador único para cada registro. Usualmente, se elige un atributo que tenga un valor único y significativo, como un número de identificación único (ID).
Claves Foráneas
Una clave foránea es un atributo en una tabla que establece una relación con la clave primaria de otra tabla. La clave foránea representa la relación entre dos tablas y permite vincular los registros de una tabla con los de otra. Al establecer una clave foránea, se crea una dependencia entre las tablas, lo que garantiza que solo se puedan establecer relaciones válidas y coherentes.
Relaciones Uno a Uno, Uno a Muchos y Muchos a Muchos
Las claves primarias y las claves foráneas permiten establecer diferentes tipos de relaciones entre las tablas:
Relación Uno a Uno
En una relación uno a uno, un registro en una tabla se asocia con un solo registro en otra tabla, y viceversa. Para establecer esta relación, la clave primaria de una tabla se convierte en la clave foránea de la otra tabla. Esto permite asociar la información de manera directa y precisa entre las tablas.
Relación Uno a Muchos
En una relación uno a muchos, un registro en una tabla se asocia con varios registros en otra tabla. La clave primaria de la tabla «uno» se convierte en la clave foránea de la tabla «muchos». Esto permite que múltiples registros en la tabla «muchos» se relacionen con un único registro en la tabla «uno».
Relación Muchos a Muchos
En una relación muchos a muchos, varios registros en una tabla se asocian con varios registros en otra tabla. Para lograr esta relación, se utiliza una tabla intermedia que contiene las claves primarias de ambas tablas. Esta tabla intermedia actúa como un puente y permite establecer múltiples relaciones entre las tablas «muchos».
Importancia de las Claves Primarias y Claves Foráneas
Las claves primarias y las claves foráneas son fundamentales para mantener la integridad y consistencia de los datos en una base de datos relacional. Estas claves garantizan la unicidad de los registros y establecen relaciones válidas y coherentes entre las tablas. Al utilizar claves primarias y claves foráneas correctamente, se evitan duplicados, se asegura la integridad referencial y se facilitan las consultas y operaciones de actualización en la base de datos.
Resumen
Las claves primarias y las claves foráneas son elementos esenciales en el modelo relacional de bases de datos. La clave primaria identifica de forma única a cada registro en una tabla, mientras que la clave foránea establece relaciones entre tablas, permitiendo asociaciones uno a uno, uno a muchos y muchos a muchos. Al utilizar correctamente estas claves, se garantiza la integridad y la consistencia de los datos, lo que es fundamental para el correcto funcionamiento de una base de datos relacional.
Normalización
La normalización es un proceso en la gestión de bases de datos que tiene como objetivo diseñar y estructurar las tablas de una base de datos relacional de manera óptima. La teoría de normalización se basa en una serie de reglas y principios que ayudan a eliminar la redundancia y la inconsistencia de los datos, garantizando así la integridad y eficiencia de la base de datos.
Formas Normales
Las formas normales son niveles de organización y estructuración de las tablas que se utilizan en la normalización. La teoría de la normalización define varias formas normales, que se denotan como 1NF, 2NF, 3NF, entre otras. Cada forma normal tiene reglas específicas que deben cumplirse para asegurar la coherencia y la integridad de los datos.
Principios de la Normalización
Los principios básicos de la normalización son los siguientes:
Primera Forma Normal (1NF)
La primera forma normal establece que los atributos en una tabla deben ser atómicos, es decir, no deben ser divisibles en partes más pequeñas. Cada atributo debe contener un solo valor, evitando así la duplicación de datos y la inconsistencia.
Segunda Forma Normal (2NF)
La segunda forma normal establece que una tabla debe cumplir con la 1NF y que ningún atributo no clave dependa parcialmente de la clave primaria. Esto significa que los atributos que no son clave deben depender completamente de la clave primaria, eliminando así la redundancia de datos.
Tercera Forma Normal (3NF)
La tercera forma normal establece que una tabla debe cumplir con la 2NF y que no debe haber dependencias transitivas entre los atributos no clave. Esto significa que los atributos no clave deben depender únicamente de la clave primaria y no de otros atributos no clave.
Ventajas de la Normalización
La normalización ofrece varias ventajas en la gestión de bases de datos:
Eliminación de la Redundancia: La normalización ayuda a eliminar la duplicación de datos, lo que ahorra espacio de almacenamiento y evita la inconsistencia de los datos.
Mejora de la Integridad: Al estructurar las tablas correctamente, se garantiza la integridad de los datos y se evitan problemas de actualización y eliminación de registros.
Facilidad de Mantenimiento: Las tablas normalizadas son más fáciles de mantener y actualizar, ya que los cambios se realizan en un solo lugar y se propagan automáticamente a través de las relaciones.
Mayor Eficiencia: Al eliminar la redundancia y las dependencias innecesarias, las consultas y operaciones de la base de datos son más eficientes y rápidas.
Consideraciones
Aunque la normalización es una práctica recomendada en la mayoría de los casos, es importante tener en cuenta que una normalización excesiva puede llevar a una fragmentación excesiva de los datos y un rendimiento deficiente en ciertos escenarios. Por lo tanto, es necesario encontrar un equilibrio adecuado entre la normalización y las necesidades y requisitos específicos de la aplicación.
Resumen
La normalización es una parte fundamental en el diseño de bases de datos relacionales. Siguiendo los principios de las formas normales, se logra una estructura coherente y eficiente que elimina la redundancia y la inconsistencia de los datos. La normalización proporciona una base sólida para garantizar la integridad y la eficiencia de las bases de datos, lo que facilita la gestión y el mantenimiento de los datos a lo largo del tiempo.